
티스토리 뷰
[크롤링이란?]
인터넷에 데이터가 방대해지면서 우리는 그걸 활용할 필요성이 높아졌습니다. 그런 정보들을 우리가 분석하기 쉽고 활용하기 쉽게 끔 데이터를 수집하는 행위를 크롤링(Crawling) 이라고 하고 크롤링하는 프로그램을 크롤러(Crawler) 라고 합니다.
원하는 데이터를 추출하는 스크래핑(Scraping)과 개념이 혼동되기도 하는데요.
사실 크롤링의 정확한 정의는 다양한 웹사이트의 페이지를 브라우징하는 작업을 말합니다.
그런데 사실상 정보를 수집하기 위해선 브라우징만 하지 않죠. 페이지 안에 있는 데이터를 추출해서 가공하는게 대부분 최종 목표입니다.
결국 크롤링 => 스크래핑의 과정으로 넘어가는 거죠.
그래서 이 두 개념이 혼용되는 것 같습니다. 해외에서는 주로 스크래핑이라고 쓰는 걸로 알고 있습니다.
크롤링을 위해서 파이썬이라는 언어를 사용하고 주로 웹페이지에서 데이터를 모아오는 작업을 수행할 예정입니다.
[크롤링의 원리]
크롤링의 원리를 알아봅시다.
먼저 웹페이지의 구성을 알아야 하는데요.
웹페이지는 HTML 문서로 작성되어 있습니다.
그리고 이 문서에는 인터페이스를 참조할 수 있는 CSS파일과 페이지 상호작용을 위한 JavaScript파일을 참조할 수 있죠.
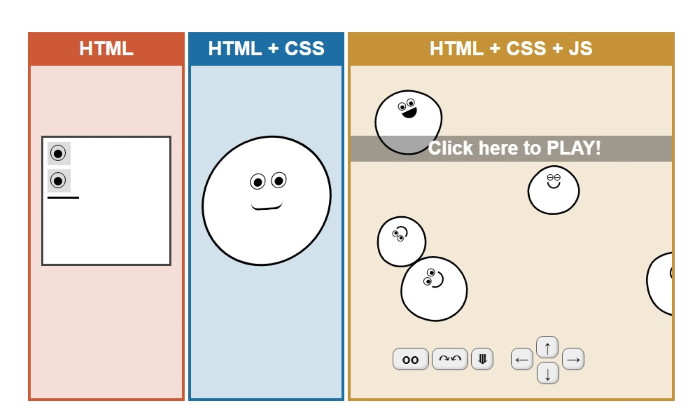
[그림1] HTML을 사용하면 문서를 작성할 수 있고, CSS를 참조하면 디자인을 활용할 수 있으며, JavaScript를 참조하면 상호작용이 가능해진다.
우리는 모든 웹페이지의 HTML 문서를 확인할 수 있습니다. 그리고 HTML 문서에 어떤 CSS 문서가 참조 되었는지, 어떤 내용이 들어가 있는지 확인할 수 있죠.
그리고 우리는 크롤러를 만들 때, HTML 태그등을 찾아서 원하는 데이터를 추출할 수 있습니다.

[그림2] 구글에 "영화"라고 검색했을 때 나오는 영화들의 목록
[그림2]에서 영화 목록을 크롤링 하고 싶을 때, 구글에 "영화"라고 검색된 페이지의 HTML문서를 확인해보면 영화제목을 어떤 HTML 태그로 사용했는지 알 수 있습니다.
class = "kltat"에 영화 이름을 넣어놨죠. 이런식으로 원하는 데이터를 추출하기 위해서 HTML 문서를 확인한 뒤 원하는 데이터를 추출할 수 있도록 크롤러를 만들면 됩니다.
'Data Science > 크롤링 & 텍스트마이닝' 카테고리의 다른 글
| [문제해결] Google API 설치시 'Cannot uninstall six' Error (with macOX) (0) | 2019.01.03 |
|---|---|
| Selenium(셀레늄) 사용하기 (2) | 2018.10.31 |
| 크롤링 시작하기 (0) | 2018.10.30 |
- query string
- Crawling
- 재귀
- logistic regression
- Linear Regression
- Machine Learning
- BFS
- Crawler
- 머신러닝
- 알고리즘
- softmax
- 크롤러
- DFS
- 크롤링
- 백준
- Express
- Queue
- 딥러닝
- LR
- neural network
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |