
티스토리 뷰
[Linear Regression]
Regression(회귀)는 지도학습에 포함되는 방법론입니다. 그 중에서도 Linear Regression을 알아볼텐데요.
Linear은 "선형"이라는 뜻을 가지고 있습니다. 선형이라 함은 배수로 늘어나는 값을 가진 것들의 모양세를 말합니다.
그래프로 표현하면 기울기를 가지고 있는 직선으로 표현됩니다.
즉, Linear Regression은 배수로 늘어나는 연속적인 값들의 데이터로 예측하는 것입니다.
값을 예측하기 전에 가설을 세울 필요가 있습니다.
Linear Regression의 경우 "이 데이터들은 배수로 늘어나는 연속적인 값들의 데이터이기 때문에 이를 만족하는 1차 함수가 있을 것이다"라는 가설입니다. 그리고 그 1차 함수를 Hypothesis라고 합니다. (Linear가 아닐 경우에는 다양한 함수가 Hypothesis가 되겠죠)

[그림1] Hypothesis의 모습은 학습의 과정을 통해 2번(정답)을 향해 간다.
자, 여기서 목표는 Hypothesis를 하나의 정답(하나의 직선)으로 추론해나가는 것이고 그 과정은 우리가 아닌 기계가 할 것입니다!
이게 Machine Learning의 과정입니다.
Hypothesis를 수식으로 표현 해보겠습니다.

기울기가 존재하는 1차 함수입니다.
Hypothesis의 모습은 W (weight)와 b (bias)에 따라 달라질 겁니다.
그렇다면 W와 b를 찾아야 할텐데요. 어떻게 찾아야 하는지 생각해봅시다.

[그림2] 가상의 선(Hypothesis)와 실제 데이터 값의 차이를 이용하자!
정답을 주고 학습을 시키는 지도학습의 특징이 여기서 나타납니다. 정답들과 Hypothesis의 차이가 가장 적은 것이 찾고자 하는 직선이 되겠죠.
여기서 Cost Function을 소개하겠습니다.

Cost Function은 우리가 세운 가설(Hypothesis)와 실제 정답과 차이가 얼마나 심한지 알려줍니다.
이해를 돕기 위해 [그림2]의 Cost Function이 도출되는 과정을 살펴보겠습니다.

우리가 예측하는 값(H(x))과 실제 정답(y)와의 차이의 제곱들의 합이 Cost값이 됩니다.
(제곱들의 합인 이유는 차이가 크면 Cost값이 확 늘어나고, 차이가 적으면 Cost값이 확 줄어들기 때문에 효율적입니다)
정리! 우리가 세운 가설과 정답의 차이가 Cost Function입니다.
그렇다면 Cost Function이 작은 것이 좋겠군요.
그렇습니다. 기계학습은 Cost Function이 가장 작은 값을 찾는 과정입니다.
즉, 주어진 "연속적인 데이터"를 통해 다른 데이터를 예측하는 기계학습(Linear Regression)을 위해서는 알맞는 Hypothesis를 찾아야 합니다.
그 Hypothesis를 찾으려면 W(weight)와 b(bias)가 Cost Function을 통해 나온 Cost값이 작아지는 방향으로 변해야 합니다.
자, 이제 개념정리를 열심히 했으니, 신나게 코딩할 시간입니다.
위의 코드는 1일 때 1, 2일 때 2, 3일 때 3인 값이 나오는 Linear한 결과값들입니다.
이 결과값들로 지도학습의 Regression 방법론을 사용할 겁니다.
x와 y라는 변수에 [1, 2, 3]의 list를 추가하고 Weight와 Bias를 설정합니다.
Weight와 Bias는 학습하면서 값이 바뀝니다. 그렇기 때문에 tf.Variable이라는 텐서플로우 메소드를 사용해서 변수를 지정해줍니다. 주로 random값으로 시작하기 때문에 1개 요소의 random값을 부여해줍니다.
hypothesis는 우리가 위에서 배운대로 수식을 사용하면 되고
cost는 reduce_mean(평균) 과 square 메소드를 통해 쉽게 표현할 수 있습니다.
이제 cost값이 줄어드는 방향으로 이동해야겠죠?
어려울 것 같지만 걱정하지마세요. 우리들이 python 모듈을 사용하는데에는 다 이유가 있습니다.
train 메소드의 GradientDescentOptimizer을 사용하면 미분값을 Optimize하게 되고 (미분값을 구하는 이유는 나중에 설명하도록 하겠습니다) minimize 메소드를 사용하면 미분값이 줄어드는 방향으로 움직이게 됩니다.
이 과정을 반복문을 통해 반복시키면 Cost값이 줄어드는 과정을 확인할 수 있습니다.
그리고 원하는 W와 b (딱히 계산해보지 않아도 우리는 답이 W = 1, b = 0 임을 알 수 있습니다)를 확인할 수 있죠.
[전체코드]
[Output]
0 14.762665 [-1.2744149] [1.1851974]
20 0.56644654 [0.09239645] [1.6837394]
40 0.39802802 [0.2550194] [1.6573844]
60 0.36043978 [0.30145413] [1.5845186]
80 0.3273476 [0.3353709] [1.5105306]
100 0.29730222 [0.3667096] [1.4395868]
120 0.27001464 [0.39648175] [1.3719358]
140 0.24523152 [0.42484593] [1.3074601]
...
...
...
1840 6.849395e-05 [0.9903878] [0.02185074]
1860 6.220707e-05 [0.99083954] [0.02082383]
1880 5.649686e-05 [0.9912701] [0.01984516]
1900 5.131116e-05 [0.9916804] [0.01891248]
1920 4.660153e-05 [0.9920714] [0.01802365]
1940 4.2325366e-05 [0.9924439] [0.01717661]
1960 3.8440172e-05 [0.9927991] [0.01636939]
1980 3.4911765e-05 [0.9931375] [0.01560006]
2000 3.170744e-05 [0.99346] [0.01486693]
1 2 3 4 5 6 7 | x = tf.placeholder(tf.float32, shape = [None]) ## shape은 N차원 텐서를 뜻하는 말로 아무차원의 값을 입력받을 수 있다. y = tf.placeholder(tf.float32, shaple = [None]) for step in range(2001): cost_val, W_val, b_val, _ = sess.run([cost, W, b, train], feed_dict = { x : [1, 2, 3, 4, 5], b : [2.1, 3.1, 4.1, 5.1, 6.1]}) if step%20 == 0: print(step, cost_val, W_val, b_val) |
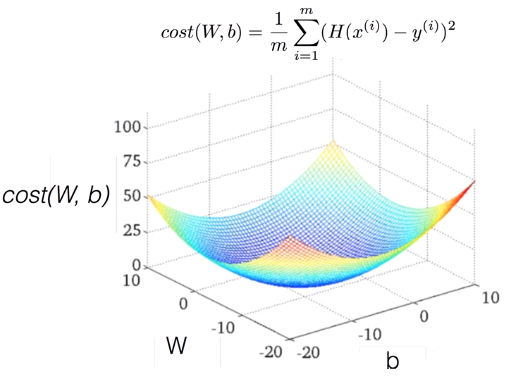
[Cost Function]
Cost Function은 어떻게 생겼을까. 그리고 cost값을 minimize하는 과정은 어떻게 일어나는지 궁금합니다.
Cost Function은 어떻게 생겼는지 궁금하면, 간단합니다! 직접 그려보죠.
Cost Function이 어떻게 생겼는지 보기 위해서 minimize하지 않고 전체의 형태를 보겠습니다.

[그림3] 우리가 찾는 점은 cost가 0인 부분. W가 1이다. (b는 생략하고 그림. b와 함께 그리면 3차원으로 표현된다)
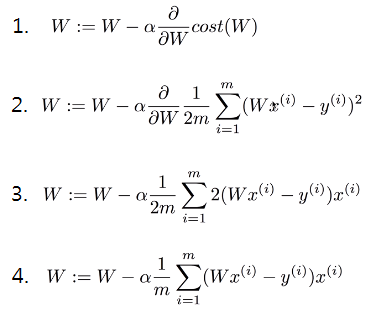
 는 learning rate(학습계수)입니다.
는 learning rate(학습계수)입니다.[그림4] 이런 형태의 Cost Function이면 대.략.난.감.
기울기가 작아지는 쪽으로만 이동하는 Gradient Decent Algorithm은 [그림4]와 같은 Cost Function에서 효과를 보지 못합니다. 하나의 웅덩이에 빠지면 다른 곳으로 이동하지 못하기 때문에 그 점이 최소 Cost인지 알지 못하죠.
[그림5] 우리는 이런 Cost Function을 원한다!
그래서 우리는 검증이 필요합니다. [그림5]와 같은 Cost Function을 가지는지 확인할 필요가 있죠.
이를 Convex Function이라고 합니다.
Cost Function이 Convex Function일 때, 우리는 Gradient Decent Algorithm을 사용할 수 있습니다.
'Data Science > Machine Learning' 카테고리의 다른 글
| Logistic Regression으로 당뇨병환자 예측 (0) | 2018.11.14 |
|---|---|
| Logistic Regression (0) | 2018.11.09 |
| Multi-Variable Linear Regression (0) | 2018.11.07 |
| Machine Learning 이란 (0) | 2018.11.01 |
| Tensorflow(텐서플로우) 설치 (0) | 2018.03.27 |
- 머신러닝
- 백준
- Express
- Crawling
- softmax
- 크롤러
- Linear Regression
- 알고리즘
- Crawler
- BFS
- DFS
- 재귀
- LR
- neural network
- logistic regression
- Queue
- query string
- 딥러닝
- 크롤링
- Machine Learning
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |