
티스토리 뷰
[ (MNIST Dataset을 만나보기 전에) Dataset 제대로 사용하기 ]
여태까지 우리는 수많은 Instance가 있는 Dataset을 통해 학습을 시켜 알맞은 Weight와 Bias를 찾고 다시 똑같은 Dataset을 주고 정답과 맞는지 정확도를 계산해왔습니다. 이게 효율적일까라는 질문에 조금 의문점이 생기는데요.
비유하자면 한 학생이 정답을 확인할 수 있는 모의고사를 치른 뒤, 채점을 하고 오답노트를 만들었습니다. 그런데 같은 시험지로 다시 모의고사를 치뤘습니다. 그리고 100점을 맞았죠! (그렇지 못한사람이 많다는건 저도 잘 알고 있습니다.) 그렇다면 이 학생은 수능도 잘 볼까요? 장담하지 못합니다.
이제 이렇게 생각해보겠습니다. 똑같이 모의고사를 치르고 오답노트를 만들었습니다. 그리고 10년치의 다른 모의고사들을 풀었더니 평균 94점이 나왔습니다. 그럼 수능을 잘 볼까요? 앞선 학생보다는 점수가 잘 나온다고 보장할 수 있겠죠.
수능을 잘보기 위해서는
1. 공부를 하기 위한 모의고사 시험지 (오답노트 체크용)
2. 나의 능력을 시험하기 위한 모의고사 시험지
3. 오답노트
4. 수능시험지
이 4가지가 필요합니다. 그리고 이것들은 다음과 비슷하다고 할 수 있습니다.
1. 공부를 하기 위한 모의고사 시험지 = Training Dataset
2. 나의 능력을 시험하기 위한 모의고사 시험지 = Testing Dataset
3. 오답노트 = Validation
4. 수능시험지 = Prediction
이렇게 Dataset을 나눠서 학습시키면 좋은 Machinelearning인지 구별할 수 있게 됩니다.

이런 Dataset이 있을 때, 두 부류로 나눕니다. 예를들어 학습을 위한 Training dataset을 20행까지 사용하고 나머지 행은 Testing dataset으로 사용하는거죠.
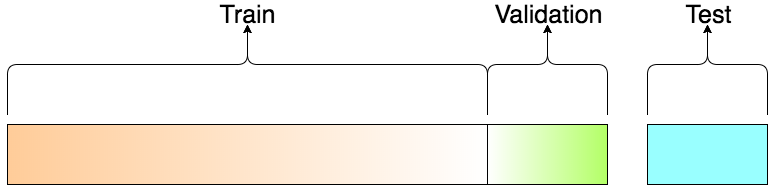
[그림1] 전체 Dataset을 세부류로 나눠서 사용합니다.
Training dataset에서도 다시한번 두가지로 나눕니다.
Validation을 통해 Learning rate 조절과 regularization을 거친 후 조금더 정교한 machine learning 모델인지 판단합니다. 오답노트의 역할을 하는거죠.
(Data의 크기가 크고 무거운;column의 개수가 많은 Data는 Validation set을 따로 정해서 사용하지만 그렇지 않은 적은 양의 Data는 Cross Validation 기법을 사용합니다. 하지만 요즘에는 그렇게 많이 사용하지 않습니다.)
[MNIST Dataset]
이제부터 Machine learning을 공부해봤다면 들어봤을 법한 것들을 배워보도록 하겠습니다.
MNIST는 Modified National Institute of Standards and Technology database의 줄인말로 손으로 쓴(혹은 발로 쓴) 숫자를 모아놓은 대형 Dataset입니다.

[그림2] 주관식 채점을 해본사람은 알것이다! 이게 얼마나 짜증나는 일인지.
이제 우리는 이 데이터를 가지고 기계학습을 진행해보겠습니다.

[그림3] 숫자 하나의 이미지의 Data 모양
MNIST에서 하나의 숫자 이미지는 저런식으로 표시되어 있습니다. 총 784개의 pixel이 있죠. 즉, 입력값이 들어갈 수 있는 자리는 784자리가 있고 이게 곧 X를 의미합니다.
Y의 자리, 즉 nb_classes는 몇일까요? 0~9의 숫자를 판별하므로 10입니다.
MNIST 데이터는 많은 파일이 복잡하게 저장되어 있어 tensorflow에서 모듈로 제공하고 있습니다.
그리고 Training dataset과 Testing dataset을 따로 저장하고 있습니다.
One-Hot encoding된 데이터로 불러올 수도 있죠.
데이터의 양이 많기 때문에 데이터를 묶어서 Training시키는게 좋습니다.
여기서 Batch라는 개념이 나오는데요. Batch는 Dataset의 한 묶음입니다. Size는 우리가 임의로 정할 수 있구요.
한 Batch가 Training을 마쳤을 때, 1 Iteration이라고 합니다. 그리고 일정한 Batch로 모든 Data를 한바퀴 돌았을 때, 1 Epoch이라고 합니다.
하나의 Epoch이 Training 될 때마다 Cost값이 얼마나 줄어드는지 확인하면 됩니다. 그래서 Epoch 하나의 평균 Cost를 출력합니다.

이 수식을 보시면 위 코드의 마지막 부분이 조금 이해가 될껍니다.
[전체코드]
'Data Science > Machine Learning' 카테고리의 다른 글
| Learning Rate (0) | 2018.11.16 |
|---|---|
| Softmax Regression을 이용해서 동물 맞추기 (0) | 2018.11.15 |
| Softmax Regression (0) | 2018.11.14 |
| Logistic Regression으로 당뇨병환자 예측 (0) | 2018.11.14 |
| Logistic Regression (0) | 2018.11.09 |
- DFS
- query string
- 크롤러
- Linear Regression
- 머신러닝
- 크롤링
- 백준
- 딥러닝
- Crawling
- LR
- neural network
- Queue
- softmax
- 재귀
- 알고리즘
- logistic regression
- Crawler
- BFS
- Express
- Machine Learning
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |